Credit Card Fraud Detection Analysis
Comprehensive classification analysis on the Feedzai BAF Dataset Suite, built for detecting fraud in highly imbalanced credit card application data. This project leverages Logistic Regression, XGBoost, and LightGBM with class balancing techniques (SMOTE and scale_pos_weight) to identify fraudulent patterns while minimizing false positives. Visualizations and model performance metrics such as precision, recall, F1, and PR AUC are included throughout.
Project Overview
Purpose
- Detect fraud in credit card applications using interpretable, high-recall models.
- Compare class balancing methods for tree-based classifiers in extreme imbalance settings.
- Visualize feature behavior and clarify performance trade-offs between models.
Dataset Background
- ~1M applications from the Feedzai BAF Dataset (synthetic, NeurIPS 2022).
- Target variable:
fraud_bool— 1 = fraud, 0 = not fraud. - Fraud prevalence: ~1.1% (extreme class imbalance).
Tech Stack
- Python (Pandas, Scikit-learn, XGBoost, LightGBM, Imbalanced-learn, Seaborn, Matplotlib)
- Jupyter Notebook for modeling and EDA
- GitHub Pages + Jekyll for publishing
Exploratory Data Analysis
Fraud Class Distribution
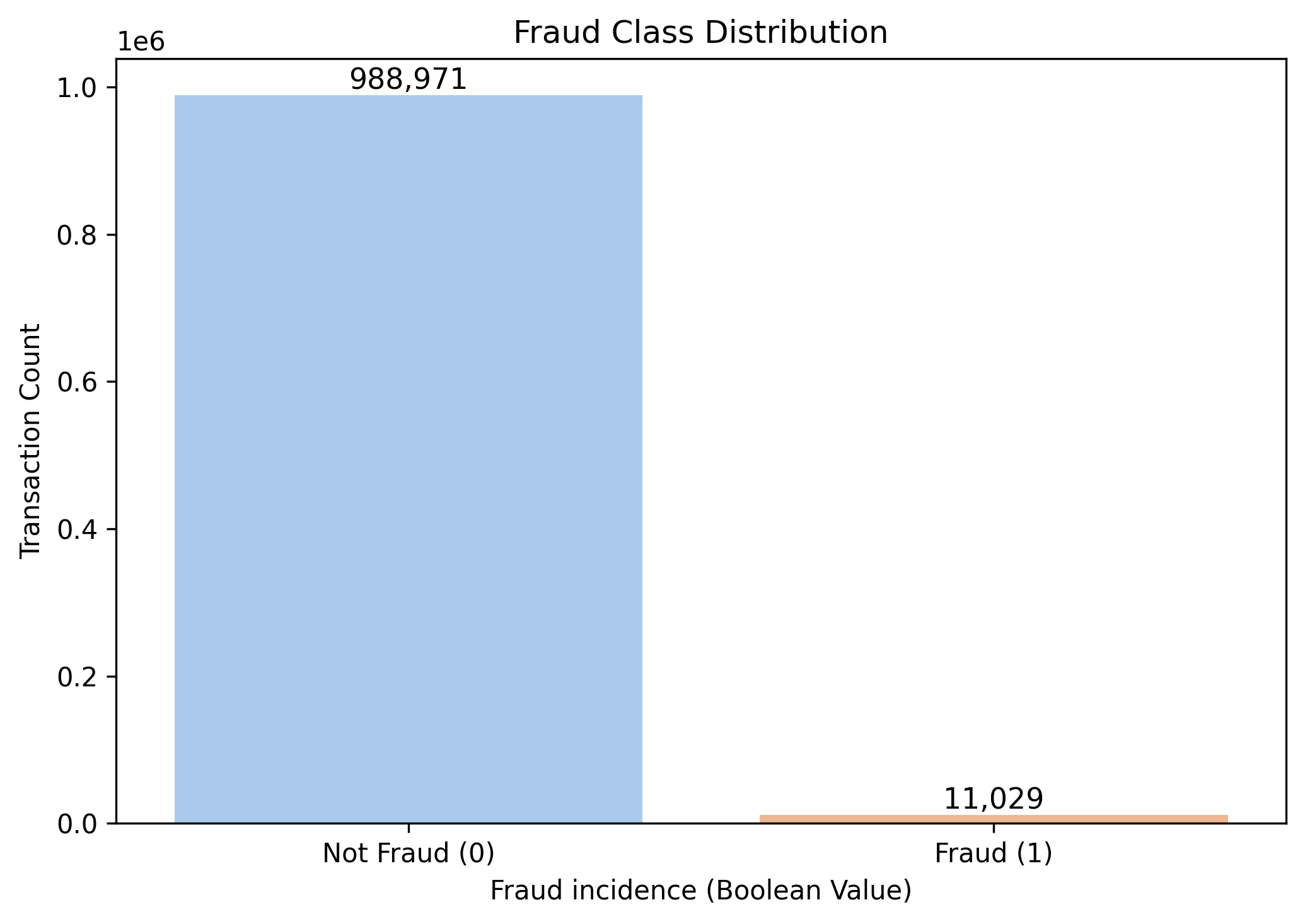
- Fraud accounts for only 1.1% of cases — justifying the use of resampling or weighting strategies.
Numerical Features by Class (KDE)
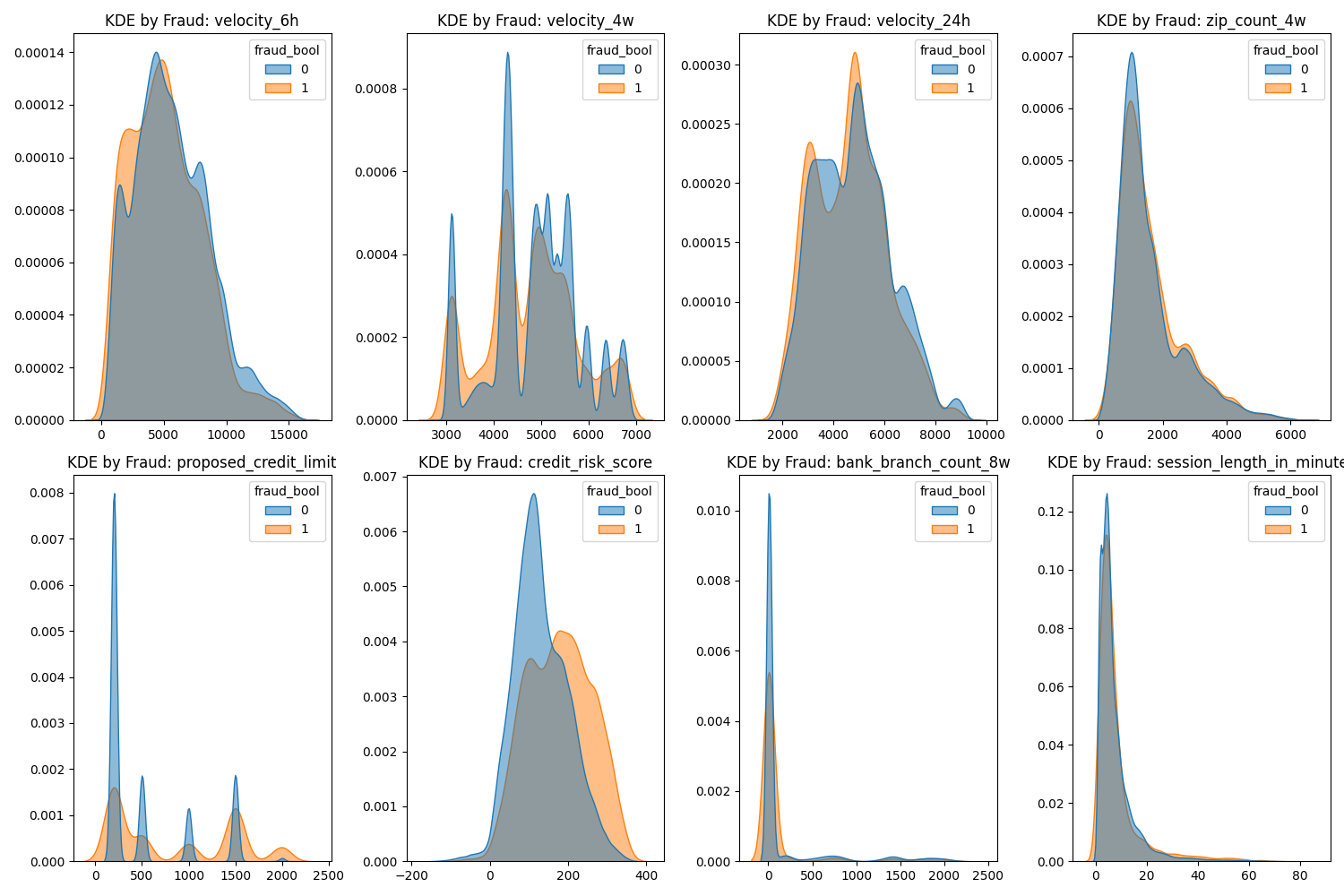
- Key indicators:
credit_risk_score,velocity_6h,session_length_in_minutes. - Even when KDE peaks are similar, subtle separation suggests high feature utility for fraud detection.
Correlation Heatmap
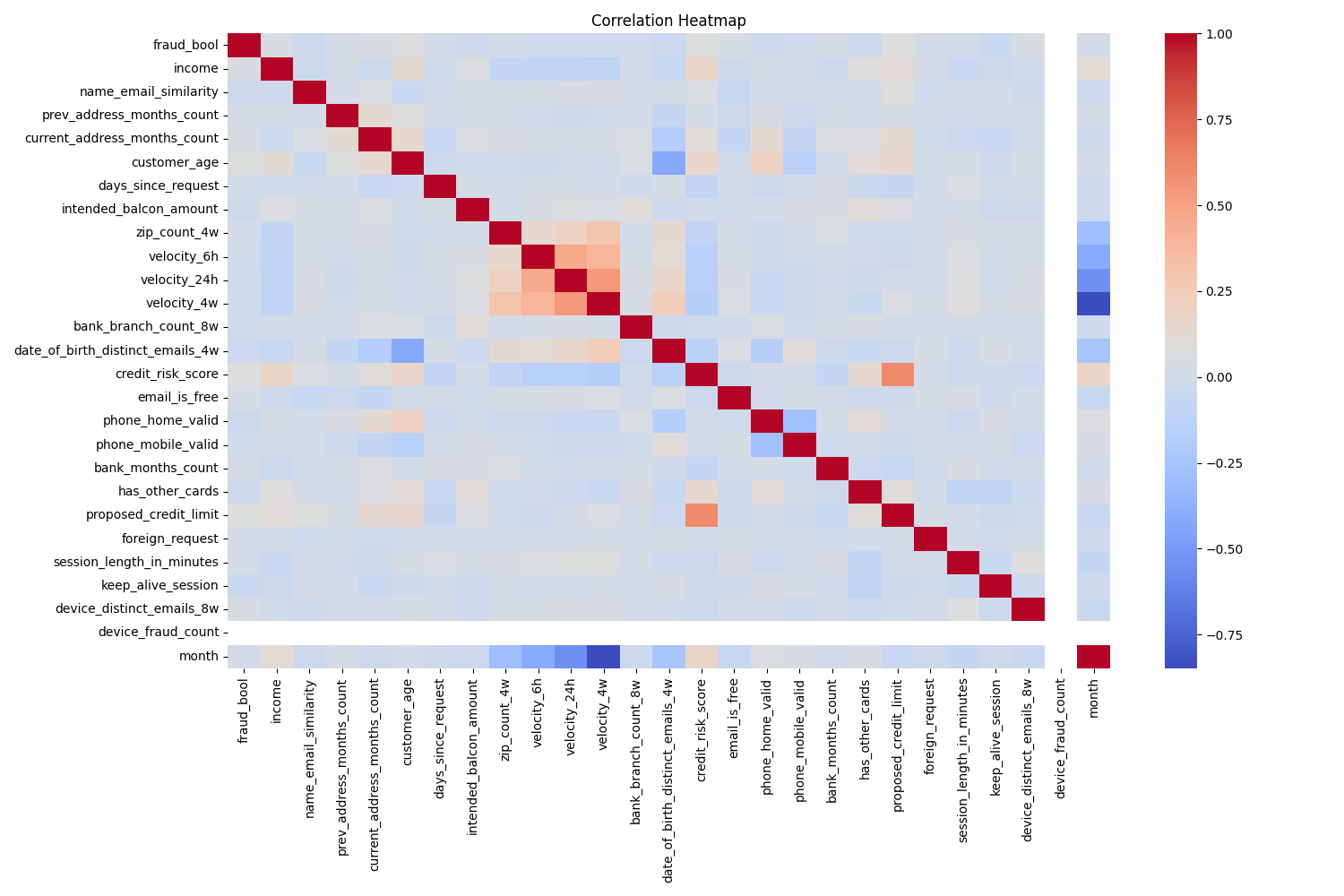
- Features like
velocity_6h,proposed_credit_limit, andcredit_risk_scoreshow moderate correlation with fraud.
Categorical Feature Insights
Note: Labels are anonymized to protect privacy but still hold predictive value.
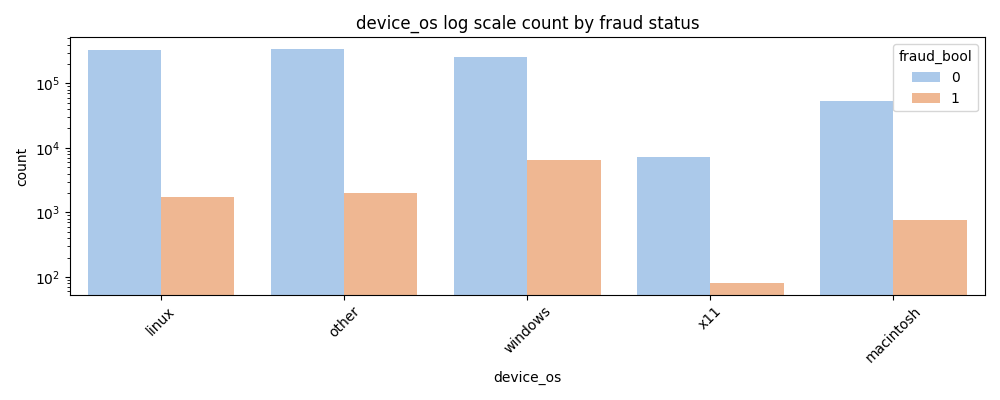
- Fraud is prevalent on Windows operating system compared to other OSes.
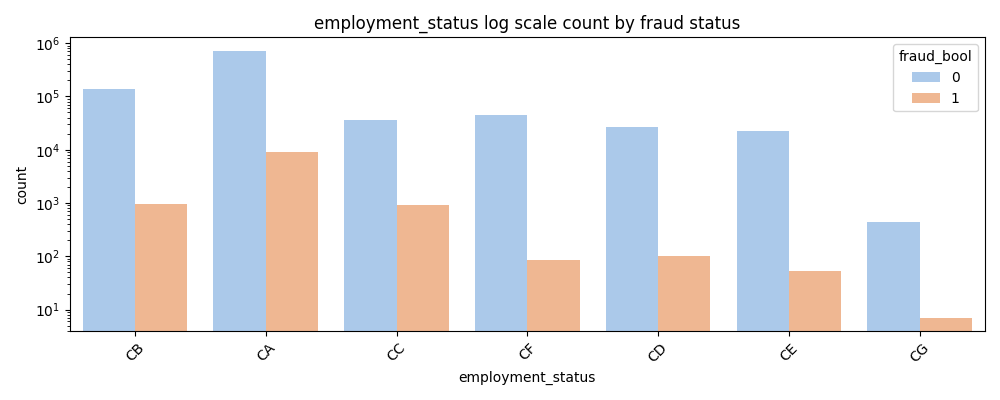
- CA employment status has an unusually high number of frauds relative to the other employment categories.
- However, it also contains the largest quantity of non-fraudulent applications, indicating general prevalence in the data.
- No single employment status category shows stark differences in fraud rates, limiting standalone predictive power.
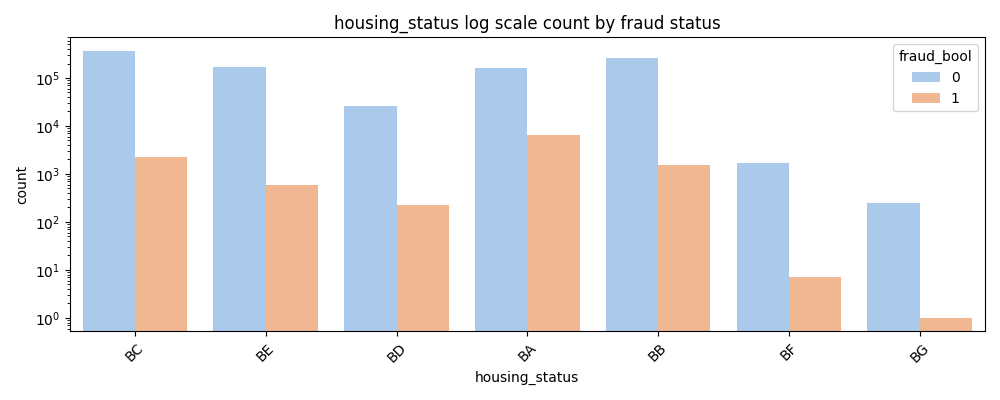
- Fraud counts are noticeably higher for BA, BB, and BC compared to other housing statuses.
- Fraud is especially rare in BG and BF even though they have significant non-fraud counts.
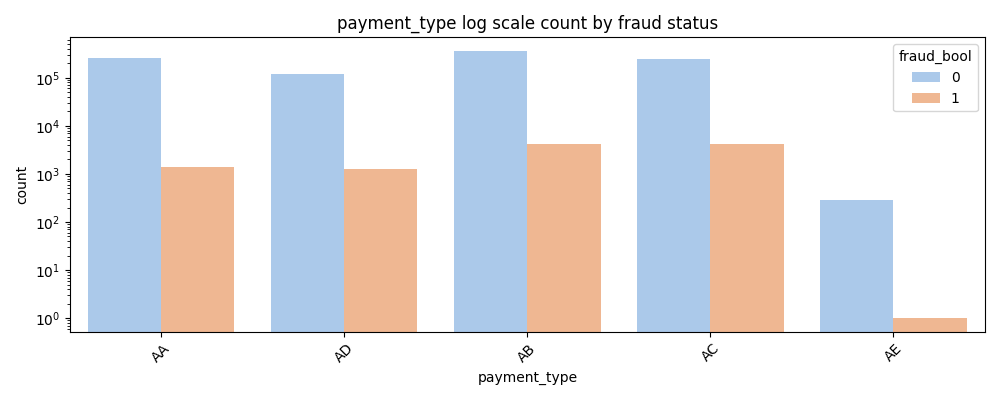
- AA, AB, AC, and AD payment types all show strong fraud representation relative to their non-fraud base.
- AE payment type is an outlier with an extremely low fraud rate despite high non-fraud volume.
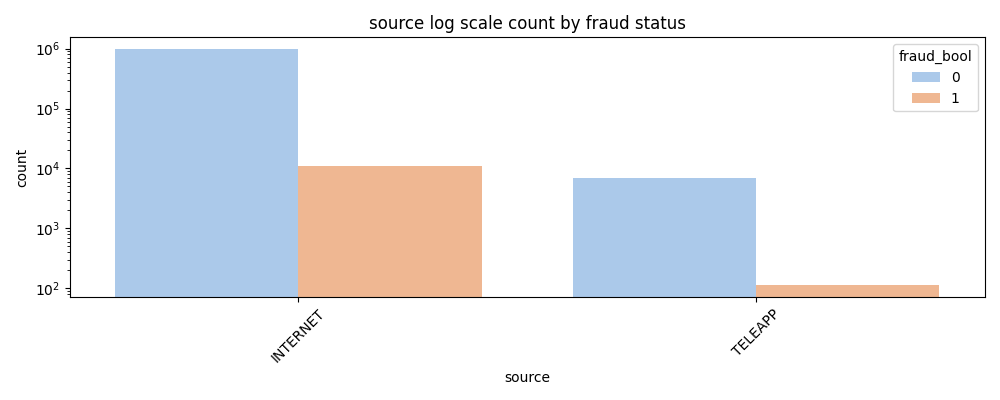
- Fraud via Internet source shows a higher total count for both fraudulent and non-fraudulent cases than Teleapp.
- While it's unclear if the internet channel is inherently riskier, it captures the majority of all applications.
Modeling and Class Imbalance Handling
Logistic Regression
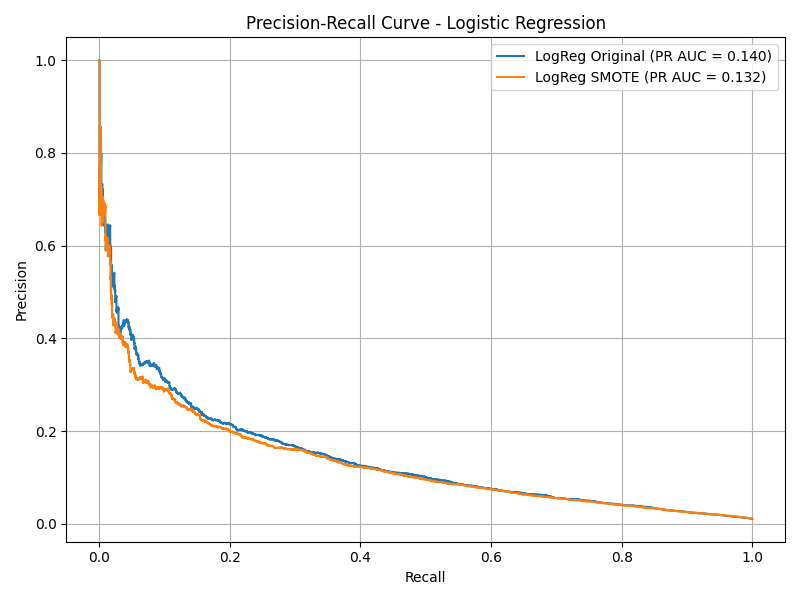
- Original: Recall = 0.01, Precision = 0.64, F1 = 0.03
- SMOTE: Recall = 0.77, Precision = 0.05, F1 = 0.09
- SMOTE increased recall from 1% to 77%, but precision dropped to just 5%.
- This version misclassified thousands of non-fraudulent applications, leading to poor real-world usability.
XGBoost
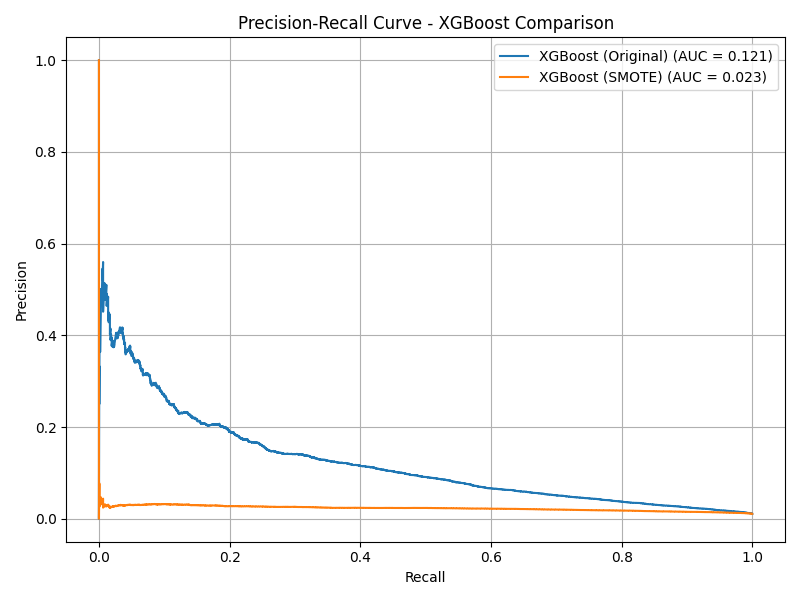
- Original: Recall = 0.03, Precision = 0.41, F1 = 0.06
- SMOTE: Recall = 0.90, Precision = 0.02, F1 = 0.03
- SMOTE severely hurt precision — model flagged over 130,000 legitimate applications as fraudulent.
- Original model retained better precision but low recall (0.03).
- Weighted model struck a middle ground — 60% recall and 7% precision, making it more viable.
LightGBM
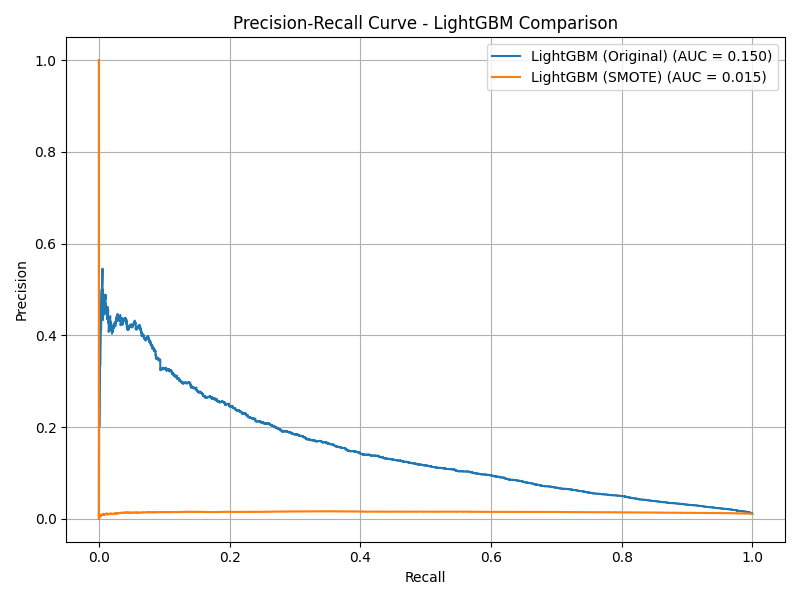
- Original: Recall = 0.05, Precision = 0.42, F1 = 0.08
- SMOTE: Recall = 0.99, Precision = 0.01, F1 = 0.02
- SMOTE pushed recall to 99% but precision to 1% — rendering the model unusable in production.
- Weighted LightGBM delivered a much better balance: 79% recall, 5% precision.
Weighted LightGBM and XGBoost
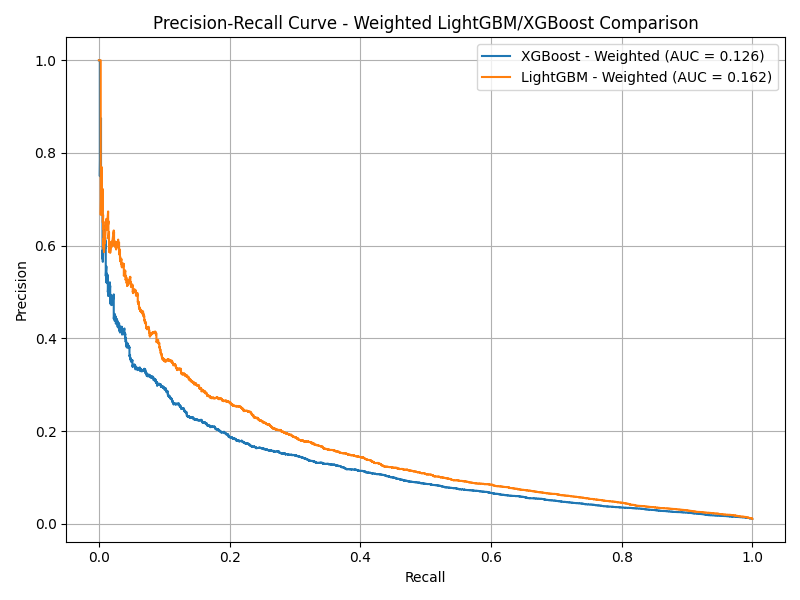
- LightGBM (Weighted): Recall = 0.79, Precision = 0.05, F1 = 0.09
- XGBoost (Weighted): Recall = 0.60, Precision = 0.07, F1 = 0.12
- Weighted LightGBM achieved the highest PR AUC (0.162), making it the best overall performer.
- Both models avoided the catastrophic overfitting seen with SMOTE.
- XGBoost’s weighted version correctly identified over 179,000 legitimate applications while keeping false positives low.
Model Evaluation Summary
| Model | Recall | Precision | F1 Score | PR AUC |
|---|---|---|---|---|
| LightGBM (Weighted) | 0.79 | 0.05 | 0.09 | 0.162 |
| XGBoost (Weighted) | 0.60 | 0.07 | 0.12 | 0.126 |
| Logistic Regression | 0.01 | 0.64 | 0.03 | 0.140 |
| LightGBM (SMOTE) | 0.99 | 0.01 | 0.02 | 0.017 |
Key Insights
- SMOTE oversampling harms precision for tree-based models due to synthetic noise overfitting.
scale_pos_weightoffers superior fraud detection trade-offs in XGBoost and LightGBM.- Velocity metrics and credit scores remain among the strongest predictors.
How to Reproduce
- Clone the repo:
git clone https://github.com/SebastianMarrero/Credit-Card-Fraud-Analysis.git - Open
Credit Card Fraud Analysis.ipynbin Jupyter - Run cells in order; visualizations will populate
/assets/images - Modify hyperparameters or balancing techniques to experiment further
Created by Sebastian Marrero — sebastianmarrero64@gmail.com — LinkedIn